Kafka Overview
Kafka Overview
- 분산 스트리밍 플랫폼
- 시스템 또는 애플리케이션간에 데이터를 안정적으로 가져 오는 실시간 스트리밍 데이터 파이프 라인 구축
- 데이터 스트림을 변환하거나 반응하는 실시간 스트리밍 애플리케이션 구축
1. 특징
- Publisher / Subscriber 모델
- 데이터 큐를 중간에 두고 서로 간 독립적으로 데이터를 생산하고 소비하는 구조
- 이런 느슨한 결합을 통해 Publisher나 Subscriber가 죽을 시, 서로 간에 의존성이 없으므로 안정적으로 데이터를 처리할 수 있음
- 고가용성(High availability) 및 확장성(Scalability)
- 클러스터로서 동작. 분산 처리를 통해 빠른 데이터 처리를 가능하게 하며 서버를 수평적으로 늘려 안정성 및 성능을 향상시키는 Scale-out이 가능
- 분산 처리(Distributed Processing)
- 파티션(Partition)이란 개념을 도입하여 여러개의 파티션을 서버들에 분산시켜 나누어 처리 가능.
2. Kafka API 종류
- Producer API : 클러스터로 Message를 전송하여 레코드의 스트림을 프로듀싱 할 수 있는 응용 프로그램에 사용
- Consumer API : 클러스터에 Message를 요청한 후 Message를 처리하는 응용 프로그램에 사용
- Stream API : 양방향 입/출력을 통해 클러스터의 메세지를 처리
- Connector API : Kafka 와 다른 응용프로그램들 간 쉽게 연결 시켜서 데이터를 보낼 수 있는 응용 프로그램에 사용
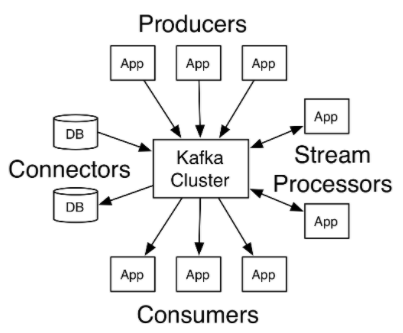
3. Kafka 구성요소 및 개념
- Processing
| 구성요소 | 의미 |
|---|---|
| Message | 분산 처리 단위 |
| Topic | Message들 집합 |
| Producer | 클러스터로 Message를 push (Flume, Fluentd ..) |
| Consumer | 클러스터의 Message를 pull |
| Partition | 클러스터에 저장된 Topic 별 레코드 스트림 |
| Topic | Message들 집합 |
| Offset | Partition내 저장된 Message 인덱스 값 |
| Lag | Consumer에서 처리해야할 Message 갯수 |
- Cluster
| 구성요소 | 의미 |
|---|---|
| Zookeeper | 클러스터의 메타데이터를 저장하는 공간 |
| Broker | 클러스터로 전송된 Message들을 각 Partition으로 분배 |
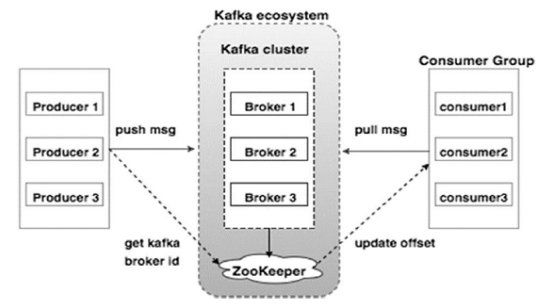
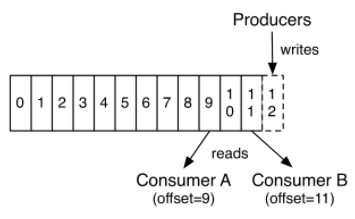
4. Kafka Flow
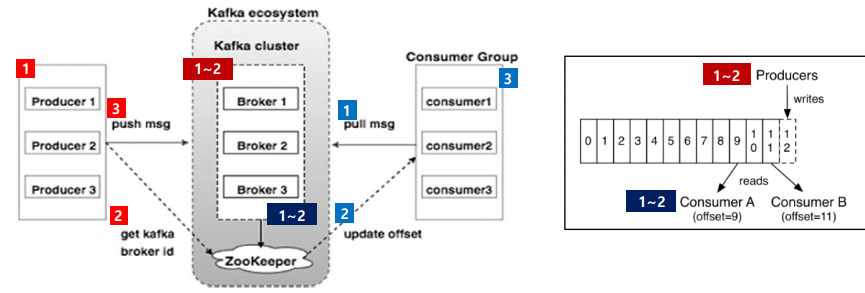 1. Producer (붉은색)
1. Producer (붉은색)
1) 로그파일 내 실시간으로 발생하는 로그 한줄 약 10KB를 파싱
2) Zookeeper에 Broker를 조회
3) Message를 Broker에 push
2. Kafka Cluster (진한 붉은색)
1) Message가 전송된 Broker가 리더로 있는 Partition에 Message를 라운드로빈 방식으로 저장
2) Partition의 추가된 Index값을 Offset으로 저장
3. Consumer (푸른색)
1) Broker에 Message 요청
2) Offset 업데이트
3) 반환된 메세지를어플리케이션 목적에 맞게 처리
4. Kafka Cluster (진한 푸른색)
1) 해당 Broker가 리더로 있는Partition의 메세지들을 라운드로빈방식으로 반환
2) 처리완료된 Partition의 Index값을 Offset으로 업데이트